
|
|
|
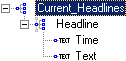
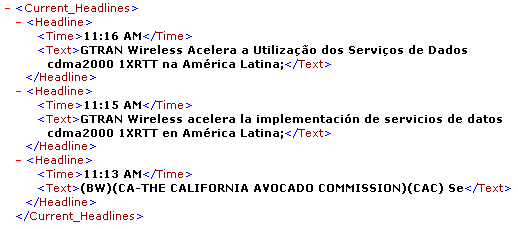
Seaglex Software has developed unique technologies for extracting, structuralizing and classifying data from the Internet and Intranets and for automating human interactions with Web sites. We leverage our revolutionary technological platform to deliver packaged vertical industry-specific products and custom information extraction solutions. Our technologies are described below. This technology allows users to convert arbitrary Internet/Intranet HTML sources into streams of structured XML data. It employs sophisticated pattern recognition algorithms to detect repetitive and recursive patterns with minimum help from the user. The parsing scripts generated at the end of the recognition process can then be automatically run to extract data from the HTML sources. These routines can extract data even if the HTML source appearance varies every time new data is retrieved. No manual programming is necessary; user interacts with the application in very much the same fashion as when browsing the Web by pointing, clicking, and annotating. The following is an XML-structured representation of news headlines as generated by our tools:
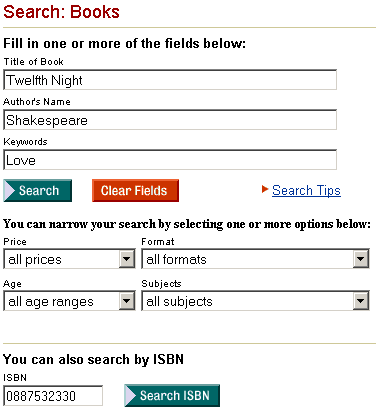
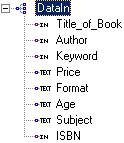
This technology records user interactions with HTML sources in such a fashion that user actions can then be replayed in repetitive cycles and on a massive scale. Recordings of user actions become parameterized procedures that can be called with different arguments through programmatic Application Programming Interfaces (API’s). Again, user interacts with the application in the Web-browsing fashion and is not required to develop any custom code. This technology also allows XML-driven automation of form input and secure login procedures by presenting all available fields as nodes of an XML schema. The following example illustrates this concept:
Creation of Uniform HTML Source Schemas and XML Schema Unification By combining HTML pattern recognition with playback/recording technology, we produce uniform XML schemas that correspond to data contained in Internet/Intranet sites. Our unification technology allows merging XML data from disparate sources into one uniform XML-structured data stream and integrating extracted information with external third-party XML data. Please see Development Tools for our unification architecture. Textual Content Filtration and Extraction By combining our data extraction techniques with sophisticated filtration methods, we are able to detect contiguous “article-like” textual content and distinguish it from collections of links, common HTML page elements, and other irrelevant “noise.” In the following examples, only the colored article on the second page will be extracted, while the first page and non-article elements on the second page, including inline graphics, will be rejected:
Statistical Data Classification Since even the information located in the “right” section of a newspaper or company site may be totally irrelevant, further content filtration should be applied to ensure very narrow focus of delivered data. For example, the real estate section of The New York Times contains mostly residential and occasional commercial real estate articles; for a commercial real estate analyst, all residential real estate news articles are “noise” that should be filtered out. We use Naïve Bayesian statistical algorithms and other machine learning techniques to distinguish between relevant textual content and “noise.” For unstructured data, we are able to speed up content processing and avoid processing duplicate information by detecting not only exactly identical documents but also those that are nearly identical, such as news articles that are reprinted or referred to by multiple sites. |




Home | Technology | WebIM Solutions | Web Harvesting | GeoRSS | RSS Aggregator | Contact Us